Choose timezone
Your profile timezone:
 This two-day workshop will take place in June 2022 at the Department of Mathematics of the University of Pisa, Italy, from Friday, June 10 to Saturday, June 11. It aims at bringing together experts in the field of numerical linear algebra.
This two-day workshop will take place in June 2022 at the Department of Mathematics of the University of Pisa, Italy, from Friday, June 10 to Saturday, June 11. It aims at bringing together experts in the field of numerical linear algebra.
The meeting is dedicated to the 60th birthday of Michele Benzi.
For those registered as online speaker, it will be possible to attend the meeting online.
The advent of Network Science was precipitated by an urgent need to decipher simple mechanisms that could explain the formation and growth of natural and man-made networks. The large-scale structural patterns of these networks systematically deviate from stylized models such as random networks or lattices in a variety of ways, which include the existence of phenomena like “small-worldness” (SW) and “scale-freeness” (SF) (see [1] and refs. therein).
Although these mechanisms explain some of the structural properties of real-world networks they also open intriguing questions. For instance, it is easy to see that the SW mechanism reduces mean path length simply by creating shortcuts, making enhanced connectivity overly dependent –and thus, fragile– on them. Likewise, SF-like networks are robust against random node removal but highly fragile against selected removal of highly connected nodes (hubs). It turns out that an optimal (geodesic) navigation of SW and SF networks tends on average to “overuse” both shortcuts or hubs, making these the first candidates to experience jamming, a property that induces a failure cascade which can severely harm the macroscopic network’s function.
Here we investigate the microscopic structure of SW and SF networks and discovered that both mechanisms generate topological bypasses connecting pairs of nodes, which facilitates the network communication beyond the topological shortest paths. We model the dynamics on the network by using the time-dependent Schrodinger equation with a tight-binding (TB) Hamiltonian H. Then, the real-time propagator $e^{-it \mathcal{H}/\hbar}$ is mapped into the thermal propagator $e^{−\beta \mathcal{H}}$, where $\beta$ is the inverse temperature of a thermal bath in which the network is submerged to. After setting appropriately the TB parameters we get that $\mathcal H = -A$, such that we define:
$$
\hspace{5cm}
\xi_{vw}(\beta) := \langle \psi_v - \psi_w | e^{\beta A} | \psi_v - \psi_w \rangle,
\hspace{5cm} (1)
$$
which accounts for the <i>resistance</i> offered by the network to
the displacement of the particle from the node $v$ to the node
$w$ at inverse temperature $\beta$. We proved that $\xi_{vw}(\beta)$ is a square Euclidean distance between the pair of nodes $v$ and $w$ [2].
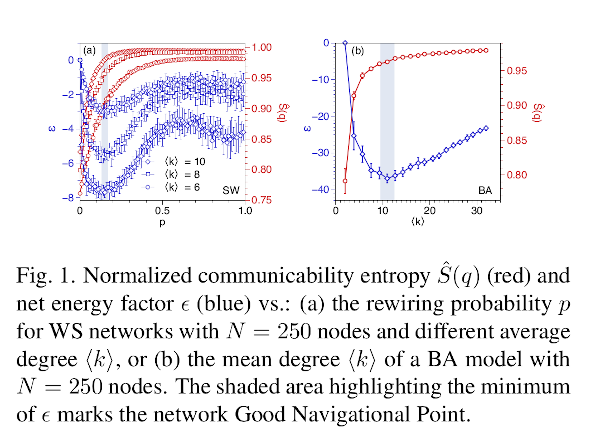
Further we define a walk-based network entropy, which accounts for the structural ordering of the network produced by the emergence of walks among pairs of nodes. Using it, we shown that both mechanisms, SW and SF, increase network entropy as a result of rocketting the choices that the particle has to navigate between every pair of nodes (see Fig. 1). Therefore, a particle navigating between a pair of nodes $v$ and $w$ can go through the topological shortest path (SP) connecting it or via some of the alternative bypasses created by the SW and SF mechanisms. We assume that the particle will “select” such a path that minimizes the thermal resistance between the two nodes. Based on $\xi_{vw}(\beta)$ we obtain the energy $\epsilon$ that a particle needs to travel between a given pair of nodes using a given path that connects them. The path for which the particle needs minimum energy among all which connect a pair of nodes is named the thermally resistive shortest paths (TRSP).
We investigate when the TRSP is favored over the SP for the navigation between pairs of nodes in a network created by the Watt-Strogatz (WS) SW mechanism as well as by the Barabasi-Albert (BA) SF one. The results are illustrated in Fig. 1. We can see that the change of the net energy factor $\epsilon$ exhibits a non-monotonic shape as a function of the rewiring probability p in the so-called small-world regime. In fact, our measure detects a minimum for $p \approx 0.15$ at which, on average, traveling through the TRSP is energetically much more favorable than traveling through the SP. We call this probability the “good navigational point” (GNP) of the network, $pGNP$. This is also observed in panel (b) for the BA model. Observe that $\epsilon$ is again non-monotonic with a minimum close to $\langle k \rangle \approx 11$, i.e. BA model for which $\langle k \rangle_{GNP} \approx 11$. Finally, we show how this property influences dynamical processes (synchronization and diffusion) taken place on the networks and investigate the existence of such bypasses in several real-world networks. Therefore we conclude that:
“a network is complex when its structure is sufficiently rich in walks connecting pairs of nodes as for TRSP emerge as
alternative routes that avoid SP and through-hubs navigation, which therefore increases network robustness against jamming”.
[1] E. Estrada, The Structure of Complex Networks. Theory and Applications (Oxford University Press, Oxford, 2011).
[2] E. Estrada, The communicability distance in graphs. Lin. Al-
gebra Appl. 436, 4317-4328 (2012)